AI翻訳は2010年代後半に飛躍的に精度が向上しました。みらい翻訳が開発するAI翻訳も2019年には、日→英翻訳がTOEIC960点レベル、英→日翻訳も900点以上のレベルに到達しています。
とはいえ、AI翻訳の特性上、最初から100%期待通りの翻訳結果になることはなく、プリエディット・ポストエディットを行うことで、AI翻訳を上手に使うことが推奨されています。翻訳精度の向上は「終わりのない挑戦」と言えますが、それでもエンジニアたちは、多くの人に「言語の壁を越える経験」を提供するため、真に生産性の高いAI翻訳を目指して、研究・開発を続けています。
そもそも生産性の高いAI翻訳とはどのようなものでしょうか?どのように生産性を評価すべきでしょうか?
みらい翻訳では、2023年12月に独自の「生産性評価」を実施しました。この記事では、従来の精度評価方法を紹介した上で、生産性評価の手法とその結果について紹介します。
これからAI翻訳の組織導入を検討される企業のDX担当の方にとっては、ツールを選定する上での、一つの基準になると考えています。
目次
AI翻訳の精度評価方法
そもそも、AI翻訳の精度はどのように評価されているのでしょうか?評価方法は単一ではなく、新しい評価手法は常に研究されており、弱点を補完し合うために組み合わせて使用されたりします。ここでは、代表的な2つの評価方法をご紹介します。
人手評価:Adequacy/Fluency評価
Adequacy/Fluency評価(*1)では、文字通り、AI翻訳が出力した翻訳文に対して、「Adequacy(適切さ、特定の目的を果たすのに十分であること)」と「Fluency(流暢さ)」の2つの尺度で翻訳の専門家が評価をするものです。
それぞれの尺度は5段階に分かれており、翻訳文がどの段階に当てはまるのか、主観的に評価します。「Adequacy」が5であれば入力した原文の意味が、漏れなくすべて伝わっていることになり、「Fluency」が5であればプロの翻訳家が翻訳した最初からその言語で書かれていたかのように「かなり読みやすい」ということを意味します。
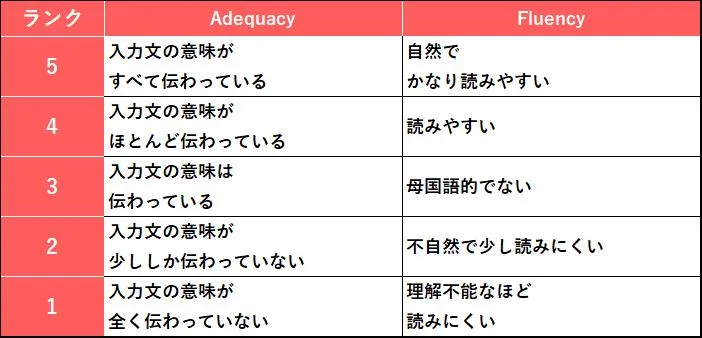 Adequacy/Fluency評価基準
Adequacy/Fluency評価基準
機械評価:BLEU(Bilingual Evaluation Understudy)
BLEU(*2)は、人手評価の手間を減らす目的で開発された評価手法で、AI翻訳が作成した翻訳文と人間が翻訳した参照翻訳文とをある計算式を用いて比較し、スコアリングします。単語の一致や連続する単語の並びの一致など、いくつかの要素が測られ、0~1の間のスコアを出します。1に近いほど、AI翻訳の翻訳文と参照翻訳文が近いことを示しています。
従来の精度評価方法の限界?新たな評価方法の確立へ
Adequacy/Fluency評価やBLEUといった評価方法は、これまで、AI翻訳を開発・改善を続ける上で、重要な役割を担ってきました。しかしながら、現在のメジャーなAI翻訳はどれも非常に高精度です。これらの評価方法で出てくる結果のわずかな差異を、複数のAI翻訳を使い比べた時に、明確に認識できる利用者はおそらくほとんどいないでしょう。
一方で、それだけ高度化したAI翻訳ですが、時に誤訳も発生します。それ故、利用者からみて不満が無いという訳ではありません。むしろ、AI翻訳の圧倒的な速さやコストの低さを評価しつつも、出力された翻訳文に対する誤訳の確認やポスト・エディット作業の手間がもっと減ればいいのに、と感じている利用者もいると認識しています。
AI翻訳である以上、利用者による確認やポスト・エディットが完全になくなるということはあり得ません(*3)。しかし、それらの作業をできる限り少なくし、より生産性向上に貢献するAI翻訳にしていくために、みらい翻訳は、これまでの評価方法とは異なる新たな評価方法が必要では?と考えました。それが「生産性評価」です。
生産性評価とは?
みらい翻訳では、「生産性に貢献できるか」を計るため、まずは外国語関連業務の中でも英語を「読む」業務にフォーカスしました。「読む」業務とは、例えば海外市場調査のために文献やメディア記事、調査報告書等を読む、海外からのメールを読む、契約書を読むなどがあり、外国語関連業務の中でも、かなりのボリュームを占めています。
「読む」生産性の向上により、作業時間の短縮、収集可能な情報量の増大が期待できることは言うまでもなく、外国語のスキル不足のために、今まで「読む」ことに携わってこなかった人も、母語に触れるかのように読むことができるようになるという可能性も広がっています。
「読む」生産性においては、利用者が「早く読めること」「内容を正しく理解できること」が重要であるとの考えに基づき、評価手法を設計しました。2023年12月~2024年1月に実施した今回の評価では、みらい翻訳の従来モデルと最新モデル(23年12月時点)の他、他社のメジャーなAI翻訳ツール①・②を比較対象としました。以下はその評価方法の概略です。
評価方法(概略)
- 全部で75個の英語ニュース文およびメール文を各翻訳サービスで和訳
- 15人の被験者に和訳文を読んでもらい、読み終わるまでの読解スピードを計測
- 上記の被験者に翻訳前の原文にまつわる問題に回答してもらいツール毎の正解率(=内容理解度)を算出
生産性評価の結果
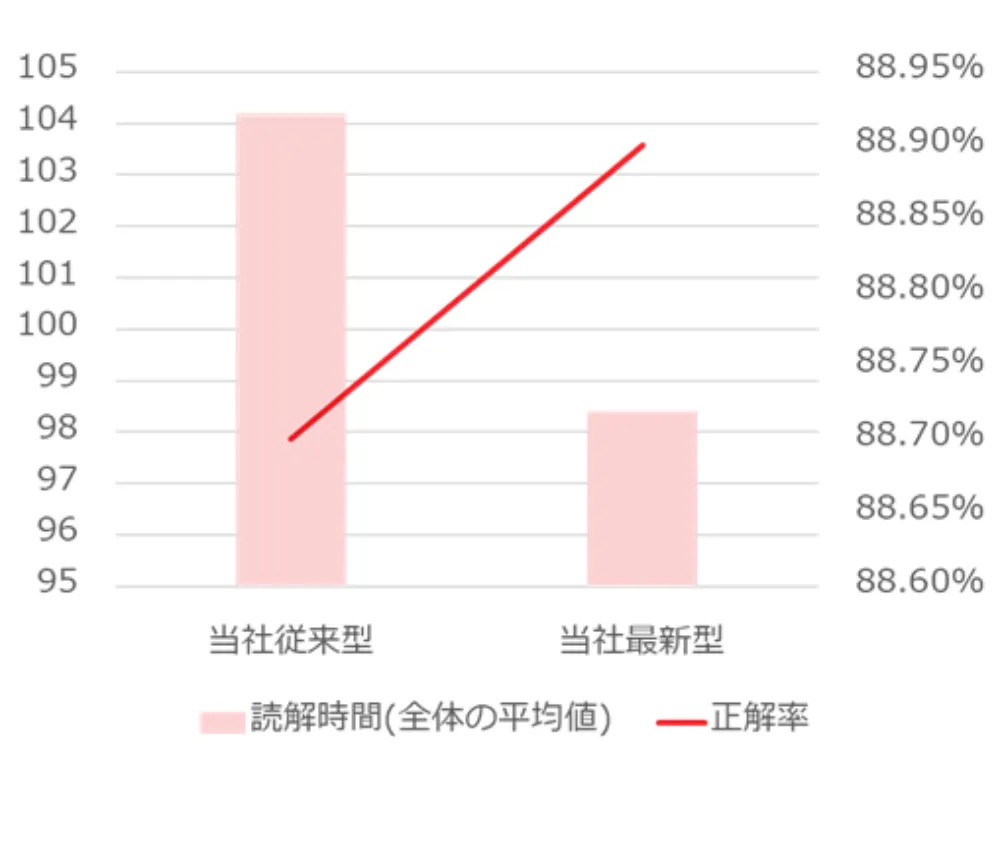
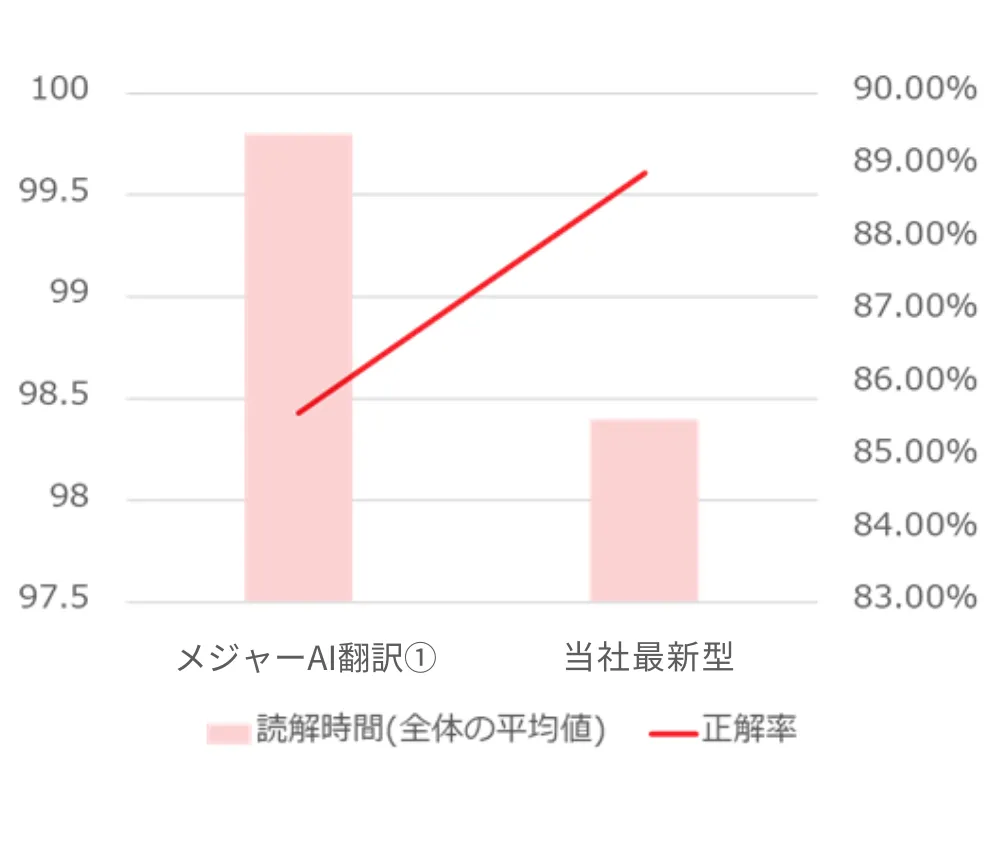
それぞれのツールの読解スピード・正解率をみらい翻訳の最新モデルと比較し、グラフ化したのが以下になります。結果として、みらい翻訳の最新モデルは、自社の従来モデルや現在公開されているAI翻訳ツール①②を上回る精度であることが分かりました。
みらい翻訳 従来モデル vs 最新モデル
メジャーAI翻訳① vs みらい翻訳 最新モデル
メジャーAI翻訳② vs みらい翻訳 最新モデル
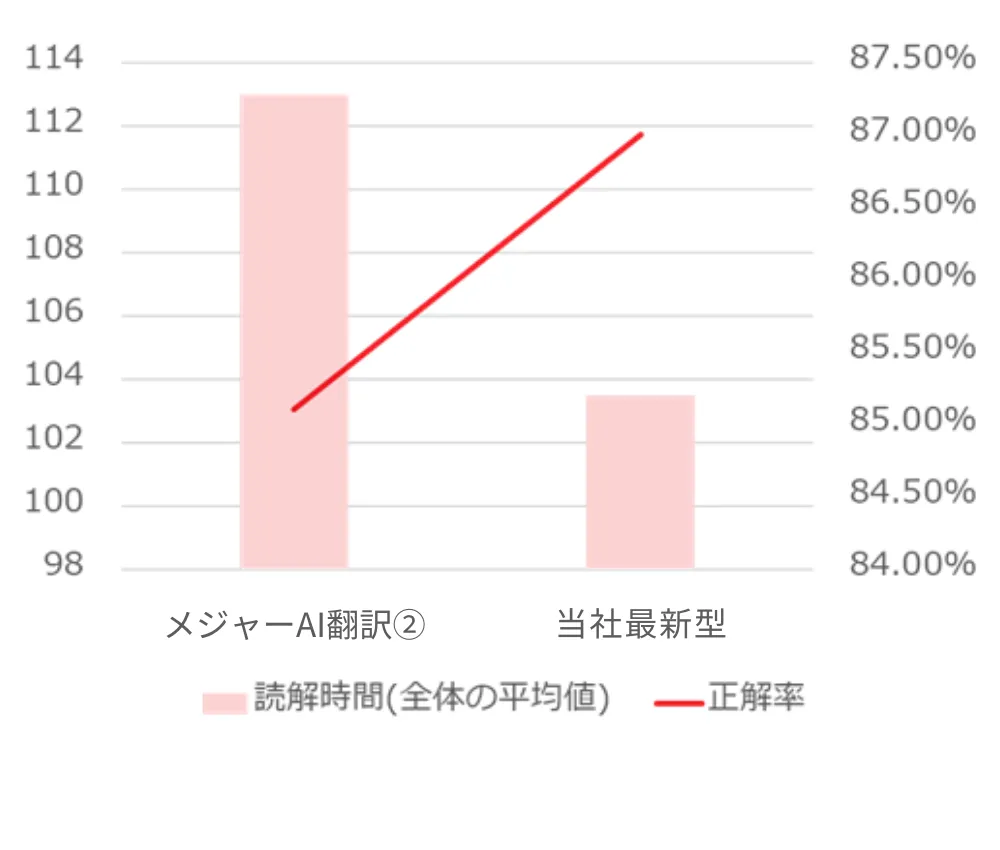
メジャーAI翻訳①との読解スピードの差は、従来型やメジャーAI翻訳②に比べると小さく、両ツールとも非常に「読みやすい」翻訳文を出力していることがうかがえます。 一方で、正解率を見てみると、みらい翻訳の最新モデルが3%以上の差をつけています。
みらい翻訳ではさらに、読解スピードや内容理解度のツール毎の差異の要因を正しく理解するため、それぞれのツールの翻訳文の分析を行いました。すると「訳抜け」や「湧き出し」などの誤訳の出現数にツール毎の違いがあることが分かりました。このような違いが正解率に関わっているようにも思えます。ただし、相関関係があるかどうかは更なる分析が必要でしょう。
まとめ
現在、さまざまなベンダーがAI翻訳ツールを提供しています。それらはニューラルネットワークを基盤にしているというところは共通ですが、周辺のプログラムやAIの学習に使用されたデータなどが異なっています。今回の生産性評価においては、ツール毎の違いにより「読む」生産性=読解スピードや内容理解にどのような影響を与えているのか、より鮮明に見ることができました。
この生産性評価は、みらい翻訳にとっては、AI翻訳を改善し続ける上での指標となり、またAI翻訳を導入しようという企業にとっては、セキュリティや費用といった項目と並び、ツール選定時の重要な判断基準にもなりえるでしょう。
(*1)「機械翻訳システム評価法の最前線」(PDF)(*2)「多言語自然言語処理研究の基礎を支える、評価尺度BLEU」
(*3)仮にAI翻訳の正確性がもとのテキストを100%正確に訳せるようになったとしても、利用する人の意図や判断を加えるという作業が無くなることはないと考えています。